
Visual Programming has recently emerged as an alternative to end-to-end black-box visual reasoning models. This type of method leverages Large Language Models (LLMs) to generate the source code for an executable computer program that solves a given problem. This strategy has the advantage of offering an interpretable reasoning path and does not require finetuning a model with task-specific data. We propose PropTest, a general strategy that improves visual programming by further using an LLM to generate code that tests for visual properties in an initial round of proposed solutions. Our method generates tests for data-type consistency, output syntax, and semantic properties. PropTest achieves comparable results to state-of-the-art methods while using publicly available LLMs. This is demonstrated across different benchmarks on visual question answering and referring expression comprehension. Particularly, PropTest improves ViperGPT by obtaining 46.1% accuracy (+6.0%) on GQA using Llama3-8B and 59.5% (+8.1%) on RefCOCO+ using CodeLlama-34B.
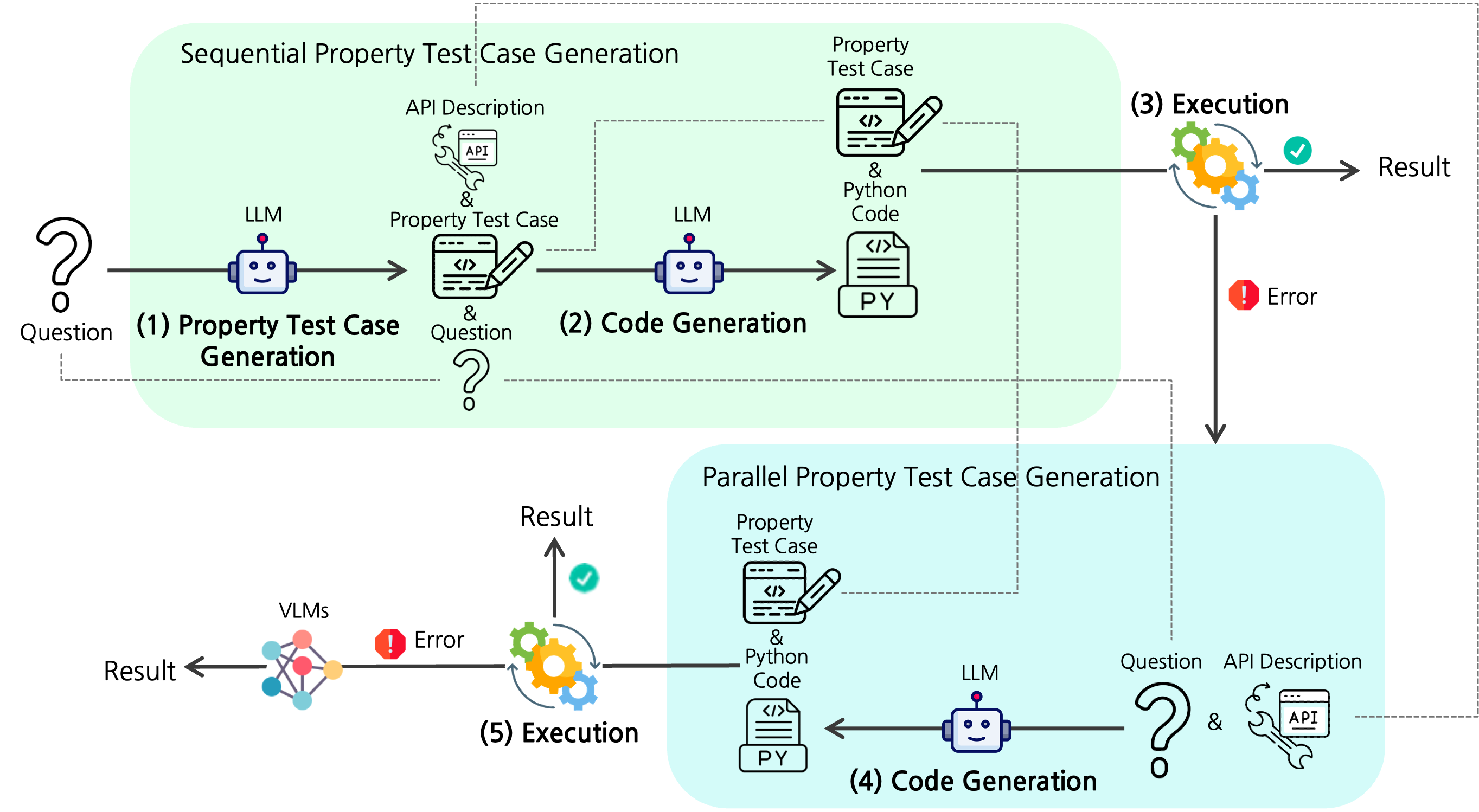
Overview of PropTest.
An overview of PropTest. Given an image and a question, the goal is to generate Python code that can be executed to get an answer. PropTest first calls an LLM to generate test cases based on the inferred properties of the answer. Then, the generated test cases are used to improve the quality of Python code.
We show some example results on GQA, A-OKVQA, RefCOCO and RefCOCO Plus where PropTest succeeds but the baseline fails. Input question and answer is shown on the left, generated property test case in the middle, and code on the right.
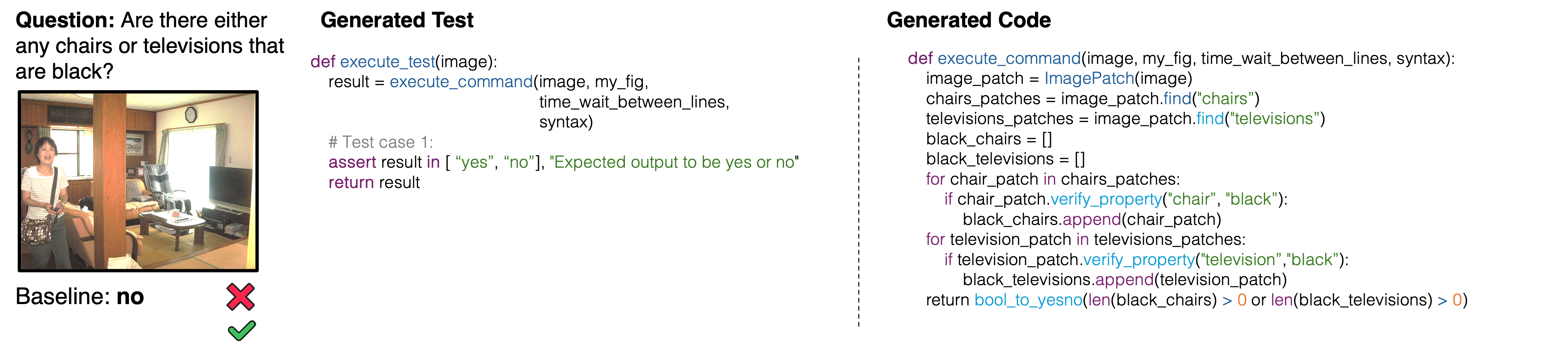
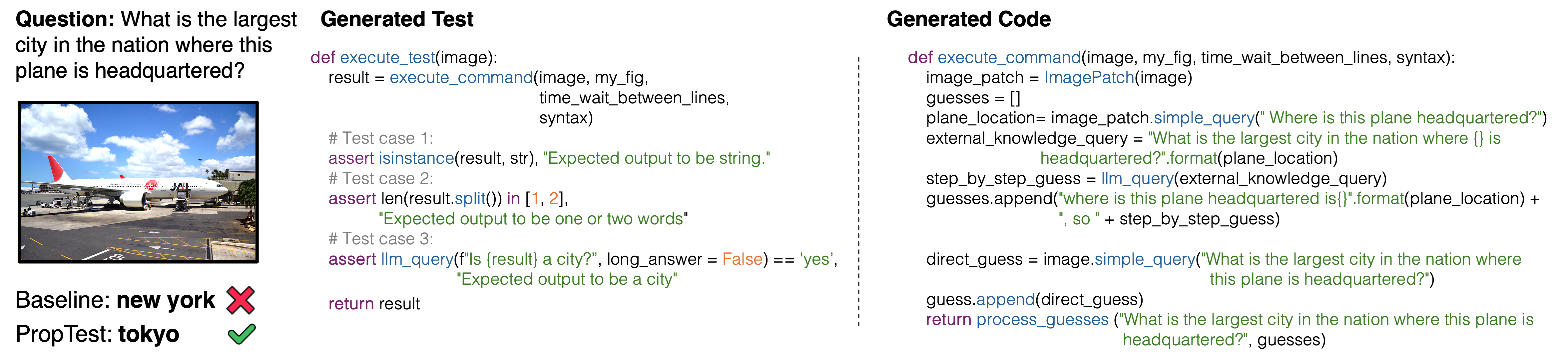
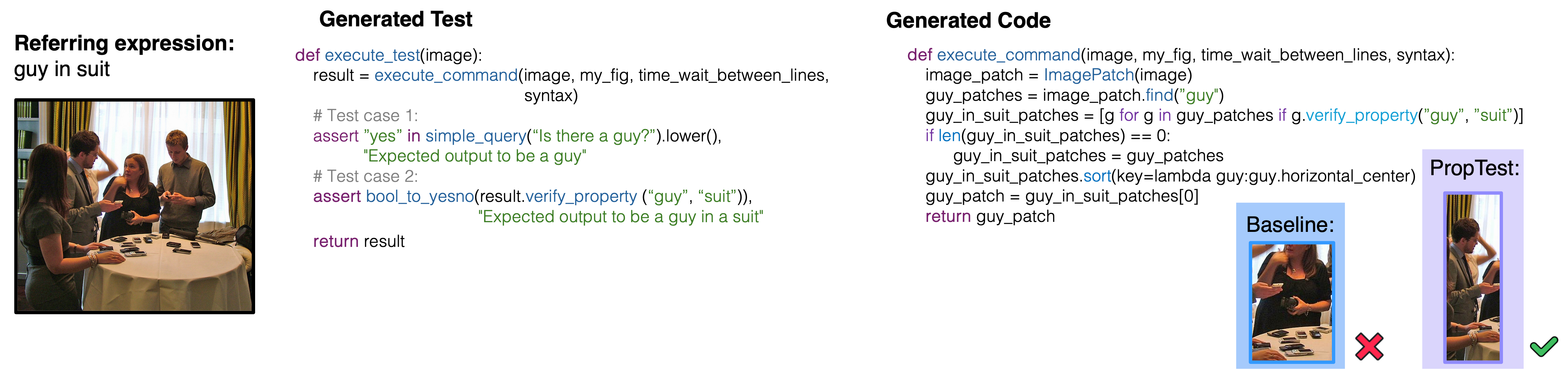

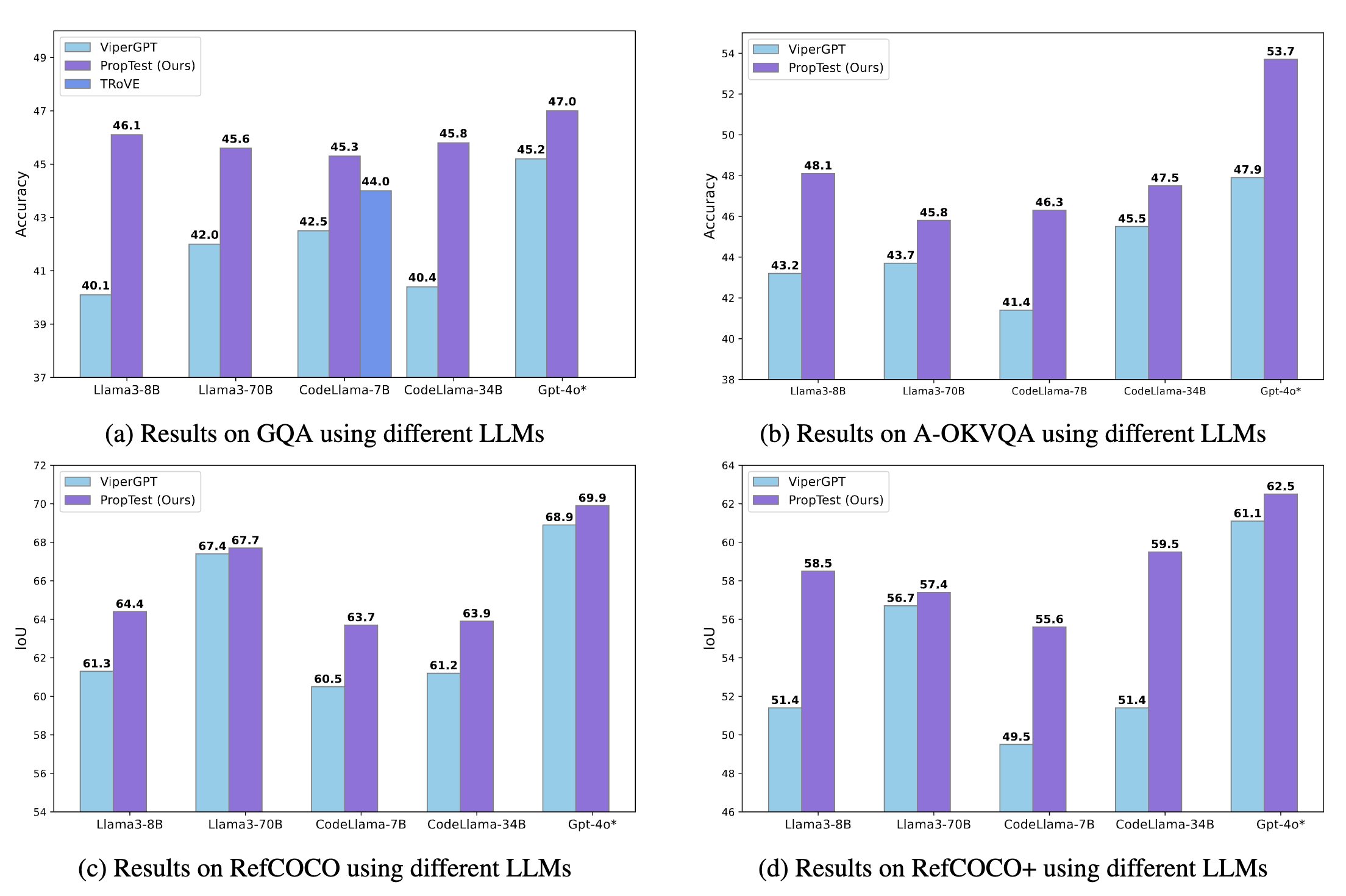
Comparison of our method against visual programming methods with different LLMs across two tasks, four benchmarks.
We report Accuracy on two visual question answering benchmarks, and IoU on two visual grounding benchmarks. GPT-4o* results are only tested on 500 subsamples.
@article{koo2024proptest,
title={PropTest: Automatic Property Testing for Improved Visual Programming},
author={Jaywon Koo and Ziyan Yang and Paola Cascante-Bonilla and Baishakhi Ray and Vicente Ordonez},
year={2024},
eprint={2403.16921},
archivePrefix={arXiv},
primaryClass={cs.CV}
}